


Eliminating VLANs and Fragility in the Underlay with Network Virtualization
This post is not intended to participate in the vendor Overlay vs. Underlay vs. Open OS vs. closed NOS but rather a network centric look at some things I am considering. The simple answer is routing scales and bridging doesn’t in my experience. As I look back at the first decade in my career I spent operating and designing Ethernet networks, the one thing that no amount of effort could solve was the inherent fragility of the broadcast domain. When I started in networking, it was the early days of the VLAN. VLANs were the magical answer to the instabilities of a single bridge in a large network and it worked fine in the linear topologies of the day. As VoIP and other data center applications critical to the business began to require redundancy. It was at that point when we should have been coming up with more effective means of dealing with L2 learning then flooding broadcast domains.
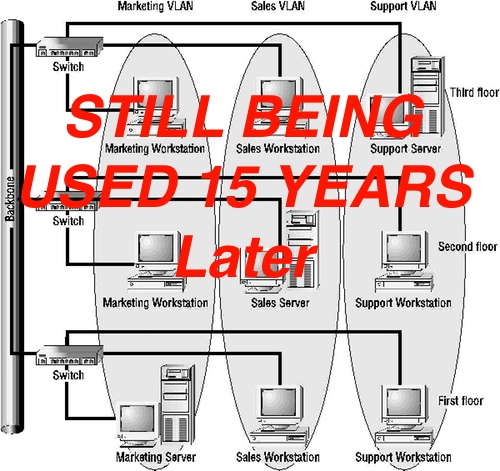

Instead, we came up with mechanisms of tricking the logical network into thinking the physical network was loop free and adjusting L2 topology timers to the edge of math to reduce convergence as much as possible. The next iteration of patching was segmenting the L2 network into smaller chunks. This was where the wheels came off. If (big if) an organization could re-address their infrastructure they were handicapping the ability to use tools in the server virtualization realm such as vMotion. And yes, while L3 failover is always the more scalable solution, most systems administrators tune you out when you are explaining why they need to gut their infrastructure to implement it.
The point of relaying my experience and pain of the L2 edge is to talk about what I am implementing in the physical networks moving forward. Routing, because it scales. Case in point, the Internet.
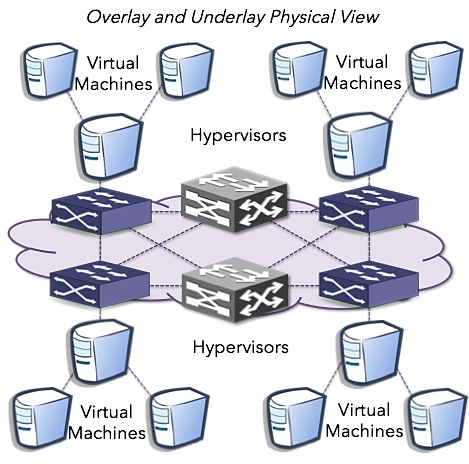
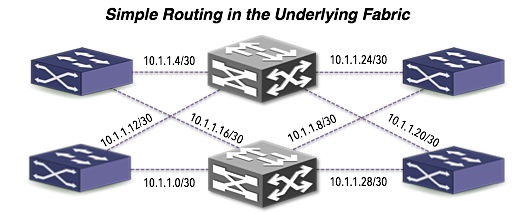
First a look at the physical layout of the overlay infrastructure. You have a phyisical network with VTEPs on the edge. VTEP IP reachability is the key networking need for overlay tunnel fabrics. Most SDN solutions other then pure OpenFlow based strategies use MAC-in-UDP w/VXLAN framing. As VXLAN evolves beyond multicast, state will be distributed via unicast which is the most coherent cloud networking vision to date. Consider the same abstraction of the data center extended to carrier NSP networks to extend network policy to CSPs.
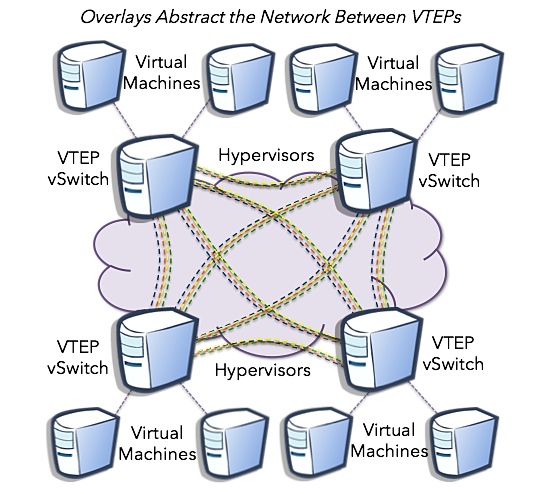
The result is a logical view after the underlay is abstracted. Each tenant has a VNI ID that represents the VXLAN segment or the tenants segment. This topology consists of VXLAN tunnels setup between hypervisors that encapsulate the tenant VNIs. This assumes all tenants are in the same datapath (bridge). Tenant flows are isolated from one another using the VXLAN VNI in a single bridge scenario. The attractiveness of one set of fully meshed VXLAN tunnels to each VTEP is it only needs one set per bridge. For example:
|
1 2 3 4 |
ovs-vsctl add-port br0 vx1 -- set interface vx1 type=vxlan options:remote_ip=192.168.1.10 ovs-vsctl add-port br0 vx1 -- set interface vx1 type=vxlan options:remote_ip=192.168.1.11 |
If you had multiple bridges for the isolation in a container model, this would establish a second datapath that would require a second set of overlay tunnels to do so that could get unruly in the count but I could maybe see a compliance use case or maybe a self-service flow space DP but for now, managing one flowspace is more manageable then multiple. The attractiveness of extracting the virtual network from the transport to a developer is not needing to be concerned with the state of the topology in the substrate. Thats not to say that isn’t critical but it simplifies matching applications and applying forwarding policy. It is also a scalable alternative to use L1 Labmdas as the substrate and stitch endpoints into a manageable and simplified topology.
VXLAN (Virtual eXtensible Local Area Network) addresses the above requirements of the Layer 2 and Layer 3 data center network infrastructure in the presence of VMs in a multitenant environment. MAC-in-UDP runs over the existing networking infrastructure and provides a means to “stretch” a Layer 2 network. In short, VXLAN is a Layer 2 overlay scheme over a Layer 3 network. Each overlay is termed a VXLAN segment. Only VMs within the same VXLAN segment can communicate with each other. Each VXLAN segment is scoped through a 24 bit segment ID, hereafter termed the VXLAN Network Identifier (VNI). This allows up to 16M VXLAN segments to coexist within the same administrative domain. In addition to a learning based control plane, there are other schemes possible for the distribution of the VTEP IP to VM MAC mapping information. Options could include a central directory based lookup by the individual VTEPs, distribution of this mapping information to the VTEPs by the central directory, and so on. These are sometimes characterized as push and pull models respectively. – VXLAN: A Framework for Overlaying Virtualized Layer 2 Networks over Layer 3 Networks- http://tools.ietf.org/html/draft-mahalingam-dutt-dcops-vxlan-04
Don’t expect to run out and slam 16 million VNIs into your local Broadcom ASIC. I have not heard of anyone capable of going over the 12-bit 4096 value yet. I also would not be surprised to see IDs swapping much like what occurs in your average switch w/ VLANs. Most switch VLAN field processor can manage only 250-500 VIDs at once. Going over that ceiling will incur performance penalties. It is also worth noting that VXLAN should take up two FIB entries if the ToR is VXLAN aware. There is also a need to single thread to the ASIC. Hardware is hard (no pun intended).
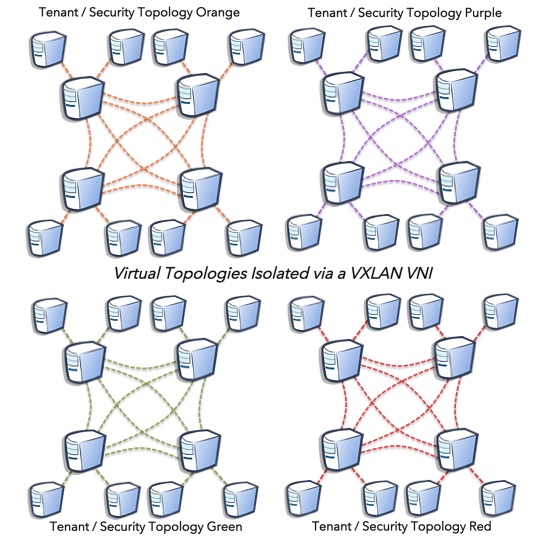
If you cannot replace the physical network, what you can potentially achieve is simplifying it. In a model where tenancy and services are extracted from VLAN IDs to VNIs in an overlay, it opens the door to either flattening the network or routing the network. Most switches can run and interoperate some form of gateway protocol and exchange VTEP reachability information. The result is minimizing the risk of unruly L2 control protocols and endpoint traffic from burning down ones network.
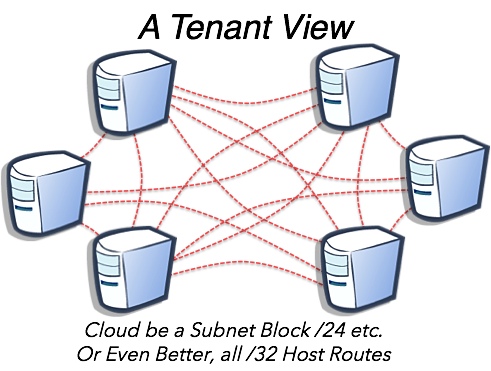
Finally the tenants view is a simple topology consisting of its hosts all being connected to one another. This is where it gets interesting. The tenants could be on one simple contiguous address block like a /24 to support vMotion or any other legacy L2 constrained feature. But since a goal of network virtualization is IP mobility, why not use a /32 host route. That address ingress/egress issues in the overlay and hacks involved in multiple gateways and prefix advertisement origination. That seems to be a logical transition to not only decouple from physical constraints in L2 networks but decouple from the constraints of an IP subnet block. Host routing with /32s is the end game. Any alternative is leaves us hacking L2 broadcast domains. I will chat on that in future posts as to get there we need an incremental path. That is the attractiveness of the network virtualization frameworks currently being proposed.
Forwarding and management control can be proactively installed into each VTEP vSwitch using messaging protocols from a controller or even distributed if state is managed between the controllers. In the case of most of the network virtualization software platforms that have been seen so far such as VMware and BigSwitch the protocols are open rather then proprietary, in the form of OpenFlow (control) and OVSDB (management). Management protocols are vital since something like OpenFlow has no sense of provisioning new tunnels or ports. It can Match on same attribute and perform a forwarding action, but it can not provision a port and configure a ports characteristics. That is why management protocols are so critical.
On the gateways. Since physical needs to drain somewhere, physical assets would need to attach to the overlay network for draining traffic outside of the overlay. This could be done in software or hardware elements. VTEP:dMAC key value pairs can be populated with any messaging protocol such as OVSDB. More information on the NSX gateway can be found in the following article:
More on NSX and VTEP Gateways →
My Reality
Network Virtualization has promise in many different areas. That said, one aspect stands out to me more then anything else, the elimination of the flood and learn driven Ethernet networks. Unruly broadcast domains set off a pager early in my career far too many times. Non-blocking MLAG approaches are a bandaid that mask fragility. Thats not to say TRILL and each vendors various mutations can also achieve a similar goal in the fabric that are really good. I am not pursuing an L2 flat fabric personally for a few reasons.
- The Isle of Hardware – I once spent two years tracking a particular model of hardware. It was a low cost MPLS switch. It was exactly what I needed for my environment. After almost an additional year of product slip, I finally got the order in. It was missing required features and was horribly bug riddled. Eventually they all got pulled out and possibly shaved a couple of months off my life. The point is, features in hardware takes time. My other problem with migrating towards a hardware driven L2 fabric is I now create an island of new and old until all hardware migrates out of the data center. This is not to say software SDN solutions are the end game, but the SDN island problem is less constrictive and drawn out.
- Interoperability – between vendors. Not to say this is unachievable, but why wait when I can run L3 ISIS today in the traditional fashion and solve L2 in the overlay. TRILL continues to scale out protocols, not layers of abstraction that hide complexity.
- Budget – wholesale replacement of DC hardware is tough in the enterprise unless it is a greenfield build. If the network is not a CapEx greenfield it is typically smaller attached
This certainly isn’t an endorsement of anything, just my experiences that are shaping one persons opinion. I am eager to see what hardware vendors are going to propose as I have tons of Enterprise and Service Provider network I am ultimately responsible for designing. There is something to be said for hard caps of fixed governed deployments. I am reserving judgement on is can hardware implement the increasing demand for business logic in the DP and a distributed CP. There may be value in implementing VTEPs in the hardware. We will see as hardware and more importantly and still missing, the software. It appears that eliminating the VLAN will happen regardless of the vendor as everyone transitions to VXLAN driven DP isolation.
As it is today, the DP is drowning in complexity without being able to programmatically simplify it. As the hardware opens up we will have new mechanisms and more importantly software that will make the case for leaving complexity in the substrate. That will presumably expand and contract over time if history holds true. In the meantime, eliminating fragility or as my friend Dave Meyer says building networks that are “evolvable” is my focus in the plumbing gig. The rest of the time is working with friends and community coding some evolution so come join us in #opendaylight #openvswitch and #opendaylight-ovsdb on irc.freenode.net and learn, learn learn.












Nice blog Brent!
I personally lean towards either FabricPath or L3 for the datacenter, to get to that simple but robust network fabric. Yes, TRILL is the multi-vendor standard, it seems to have potential scaling issues compared to FabricPath (amount of MAC learning by the TRILL fabric switches).
There’s a certain irony to the fact that as of maybe 2 years ago we were hearing “flat datacenter, VLANs go everywhere” from vendors, and now with VXLAN, we may be starting to hear “L3 datacenter”.
Hi Pete! Great to hear from you. I think it will certainly be a long funnel. Systems architectures are still reliant on the subnet for everything. Transitioning to the application as the logical grouping should be attractive. While host routes in the overlay will decouple for mobility nicely, it would also break existing tools. vMotion is one of those I don’t see sysadmins looking to give up unfortunately so we will flood a while longer it seems 🙂
Thanks for stopping by Pete and in case there is anyone that hasn’t seen Pete’s writing go here ASAP:
http://www.netcraftsmen.net/blogs.html
Cheers,
-Brnt